Can AI-Powered Trading Bots Actually Profit in 2026? A Reality Check Using Live-Market Frictions
If you're evaluating AI trading bots in 2026, the biggest mistake is asking whether the bot is “smart.” That is not the real test.
The real test is harsher: does the edge survive live trading?
That means surviving spreads, commissions, slippage, swap or financing charges, execution delays, and shifting market conditions. Some AI-powered trading bots do make money. But far fewer do than marketing suggests, and many systems that look outstanding in simulation turn out to be research artifacts rather than tradable strategies.[^1]
A better way to think about it is simple: a bot does not profit because it uses AI. It profits only if its edge is both real and executable. That distinction matters even more in 2026 because retail access to AI tools has improved, but competition and commercialization have improved too.
Can AI-powered trading bots actually profit in 2026?
The short answer: yes, but less often than marketing suggests
Yes, AI-powered trading bots can generate real profits in 2026.
But that answer needs context. A strategy can be profitable in principle and still be a poor product for a retail buyer. The seller may be using different execution, lower fees, a different broker, more capital, or simply presenting a favorable slice of history.
So the more useful answer is this: some bots profit, many claims are overstated, and the burden of proof should be high.
The real question is whether the edge survives live-market frictions
A small statistical edge in a backtest does not automatically translate into live profitability. In real markets, execution quality matters. FINRA’s order execution guidance exists for a reason: the price you expect and the price you get are often different.[^2]
That gap is where many bots fail.
A short-term forex bot might show a theoretical edge of 0.4 pips per trade in simulation. That can disappear quickly if spreads widen by 0.2 pips, slippage adds another 0.2 to 0.4 pips, and commissions consume what remains. At that point, the strategy was never robust. It was just tested in conditions that were too clean.
What “profit” really means in algorithmic trading

Gross edge vs net edge
Gross edge is the strategy’s raw advantage before costs. Net edge is what remains after real-world costs.
That distinction changes everything.
A bot that makes 18% gross annually but loses 11% to spreads, commissions, slippage, and financing costs is not an 18% strategy. It is a 7% strategy before taxes and before accounting for operational risk.
Why costs change the answer
Retail traders often focus on commissions because they are visible. But spreads are often the bigger hidden cost, especially in forex, CFDs, and high-turnover crypto systems. Slippage can be worse because it tends to appear when the strategy most needs reliable execution.
Then there are overnight swap charges, financing costs, borrow fees for some short strategies, and taxes depending on jurisdiction. Any one of these may look manageable. Together, they can wipe out a thin edge.
That is why serious performance claims should be net of all material costs, not just platform fees.
Profitability also depends on drawdowns and capital efficiency
A bot is not attractive simply because it made money.
If one bot returns 22% with a 40% drawdown and another returns 11% with a 9% drawdown, the second may be the better strategy for most traders. It creates less capital stress, depends less on leverage, and is easier to survive psychologically.
The better question is not just “did it profit?” but “what did it require in drawdown, margin usage, and risk of ruin?”
Why backtests look better than live trading

Backtests usually assume better fills than real markets deliver
Many backtests quietly assume near-ideal execution: constant spreads, no queue-position issues, no partial fills, and little delay between signal and fill. That may be acceptable for early research, but not for judging deployable performance.
In live trading, spreads widen, especially around news, session opens, and unstable liquidity. Fill quality also changes by broker, venue, and order type. In U.S. equities, SEC Rule 605 reports exist because execution quality is measurable and not uniform.[^3]
Overfitting and data leakage create false confidence
A lot of “AI trading” performance is really model-selection theater.
Researchers such as Bailey, Borwein, López de Prado, and Zhu have shown that backtests are highly vulnerable to multiple testing and false discoveries.[^4] If enough variations are tried, one will almost always look brilliant in-sample. That does not mean the edge is real.
Data leakage makes the problem worse. If future information slips into training data, even indirectly, the model may appear predictive while effectively cheating. Survivorship bias, revised data, unrealistic preprocessing, and endless parameter tuning all create the same illusion: confidence without robustness.
Paper alpha often disappears once execution enters the picture
A useful phrase to remember is this: model performance is not executable performance.
A system may identify a real pattern, but if the edge per trade is smaller than realistic round-trip cost, it was never tradable. This is especially common in scalping systems sold with beautiful equity curves and little discussion of spread behavior or slippage assumptions.
The four frictions that break many trading bots
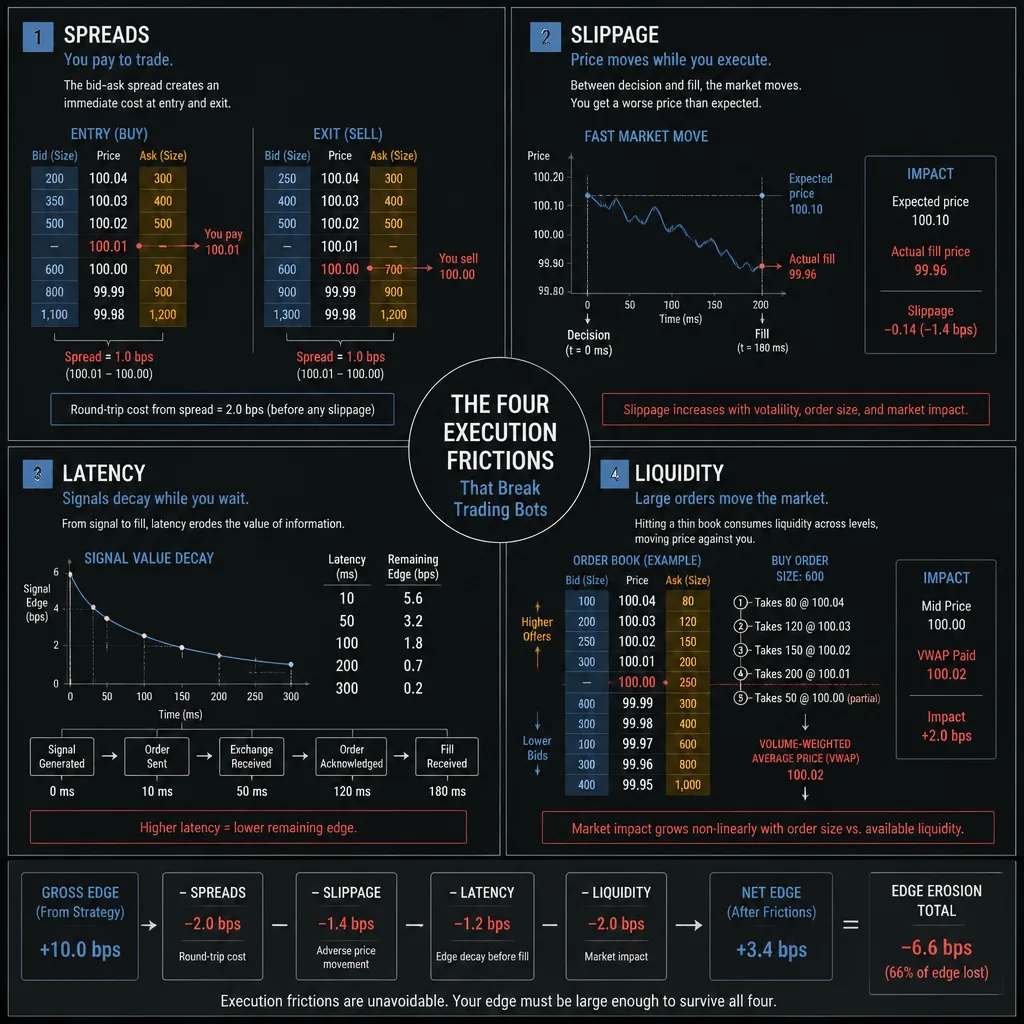
Spreads
Every round trip starts at a disadvantage because you cross the bid-ask spread. In high-turnover systems, even small changes matter.
A strategy taking 200 trades a week with a narrow expected gain per trade is highly sensitive to spread widening. A small broker difference can be enough to decide whether the system survives.
Slippage
Slippage is not just occasional bad luck. For some strategies, it is structural.
Momentum bots often enter when prices are moving quickly, which is exactly when fills tend to worsen. Exit logic matters too. If stops trigger during fast moves, realized losses may be much larger than tested losses.
This is one reason demo performance is weak evidence. Demo fills often do not reproduce the adverse selection of live markets.
Latency
For ultra-short-horizon systems, infrastructure can matter more than prediction quality.
A bot trying to exploit a fleeting imbalance may lose its entire edge if the signal decays in milliseconds and the trader is routing through a standard retail setup. In that segment, institutional firms usually have a structural advantage through faster access, better routing, and more stable execution stacks.
Liquidity
A bot may work on a small account and fail as size grows. It may work during liquid hours and fail overnight. It may look stable on major FX pairs and break on thinner instruments.
Retail traders with small positions often avoid major market impact in highly liquid products. But liquidity still matters because fill probability, quote stability, and spread behavior all change with time of day and volatility.
Why AI bots often fail during regime shifts
Volatility changes can break sizing and signal reliability
A strategy trained in calm conditions may fail when realized volatility doubles. Signals get noisier, stops are hit more easily, and sizing logic built on older assumptions becomes dangerous.
Often the problem blamed on “bad predictions” is really failed risk adaptation.
Correlation shifts break models trained on stable relationships
Pairs, basket, and multi-asset systems often rely on relationships that appear stable until they are not. Correlations can weaken, reverse, or become unstable during crises, policy shocks, or crowded unwinds.
That means yesterday’s learned relationship can become tomorrow’s source of loss.
Structural changes matter more than slight model improvements
This is one of the least appreciated truths in AI trading.
A model that is 3% more accurate on historical classification tasks can still underperform a simpler system if the market’s underlying structure changes. Slightly better prediction does not save a strategy whose assumptions about execution, volatility, or cross-asset behavior no longer hold.
Adaptation is possible, but not automatic
Some machine learning systems can adapt faster than fixed rule-based models. That is a fair counterargument.
But “adaptive” is one of the most overused words in bot marketing. Real adaptation requires controlled retraining, out-of-sample validation, walk-forward testing, and risk limits when the model begins to drift. It is not magic, and it does not remove the need for live proof.[^5]
A practical framework: edge, execution, and regime robustness
A bot needs all three
A simple framework cuts through most sales language.
A bot deserves trust only if it passes three tests:
- Signal edge: the pattern appears real, persistent, and not obviously the product of overfitting or leakage.
- Execution survivability: the edge remains positive after realistic costs, delays, and fill assumptions.
- Regime robustness: the strategy behaves acceptably across different volatility states, market types, and out-of-sample periods.
Miss one of the three, and the system is fragile.
How to use this framework
When you see a bot claim, ask three direct questions:
- Is the signal believable?
- Is it still profitable after realistic execution?
- Has it survived more than one kind of market?
That shifts attention from flashy equity curves to actual tradability.
What evidence is actually credible
Verified live track records
Platforms like Myfxbook and FX Blue can improve transparency.[^6] They are far better than screenshots because they can show history, drawdowns, trade frequency, and account behavior.
Still, they are not perfect proof. They do not eliminate cherry-picking, short sample bias, or midstream strategy changes.
Broker statements with enough history
A proper broker statement can reveal what marketing pages often hide: commission drag, swap charges, lot escalation, deposit timing, and whether returns came from a small number of outsized trades.
If the account has only a few months of history, or the seller refuses to provide enough detail to inspect costs and drawdowns, skepticism is justified.
Forward tests across different conditions
Small real-money forward tests are far more useful than polished demos. They capture slippage, spread variation, and execution delays.
A better standard is not “did it make money this month?” but “did live performance roughly match cost-adjusted expectations across different conditions?”
Why short samples and screenshots are weak evidence
A four-week winning streak proves very little. So does a demo account. So do cropped screenshots that show returns but hide drawdown and trade history.
A strategy may be valid and still not have enough evidence yet. That is fine. The problem is presenting weak evidence as strong proof.
How to judge an AI bot before risking money
Questions to ask
Before using real capital, ask:
- What data was used, and how was leakage prevented?
- Were spreads, commissions, slippage, and financing costs modeled realistically?
- Was the strategy tested in the same asset class and execution environment where it will trade?
- How sensitive are results to wider spreads or worse fills?
- What happened during stressed periods, not just normal ones?
- Is there walk-forward or out-of-sample evidence?
If the seller cannot answer basic questions like these, the strategy has not earned trust.
Metrics that matter more than headline returns
Headline return is one of the least useful metrics on its own.
More informative measures include expectancy per trade, average trade versus total round-trip cost, maximum drawdown, profit factor, Sharpe or Sortino ratio, turnover, and stability across subperiods. Win rate matters far less than most buyers assume.
A bot with a 78% win rate can still be terrible if it has fat-tailed losses or tiny average winners consumed by costs.
Red flags in marketing claims
Be especially cautious if you see:
- guaranteed returns
- very high win rates with no drawdown context
- no verified live record
- screenshots instead of statements
- vague claims that the AI “adapts automatically”
- hidden broker dependency
- martingale, grid, or averaging-down recovery logic
- heavy focus on monthly returns while ignoring tail risk
One more red flag: if a widely sold bot depends on very precise entries in a thinner market, commercialization itself may erode the edge.
Who has a realistic chance of success with AI trading bots?
Institutional firms vs retail traders
Institutions dominate the speed-sensitive end of the market. If a strategy depends on ultra-low latency, complex routing, or tiny microstructure edges, retail traders are usually outmatched.
That is not pessimism. It is market structure.
Where retail traders can still compete
Retail traders have a better chance in slower systems where the signal horizon is long enough that spread and latency consume a smaller share of the expected edge.
That can include higher-timeframe trend following, swing systems in liquid instruments, and narrowly defined rule-based models with disciplined risk control.
Why simpler systems may outperform fragile “AI” strategies
A simple system with a modest but durable edge often beats a sophisticated black box with almost no margin of safety.
That is one of the quieter truths in systematic trading. Complexity can improve research performance while making live deployment more brittle. For many retail traders, robustness matters more than novelty.
Bottom line
AI-powered trading bots can profit in 2026. But the ones worth taking seriously are not the ones with the prettiest backtests or the loudest claims. They are the ones whose edge survives costs, execution, and changing market regimes.
If you remember one thing, make it this: trust live, net-of-friction evidence over elegant simulation.
A bot should prove three things before it earns serious capital: that its signal is real, that execution does not destroy the edge, and that it can survive more than one kind of market. In practice, that means favoring verified live records, broker-level evidence, small real-money forward tests, and slower strategies with enough margin of safety to absorb friction.
AI may help generate signals. It does not repeal the laws of trading.
FAQ
Can AI-powered trading bots actually make money in 2026?
Yes, some can. But far fewer do than marketing suggests. The key issue is not whether a bot looks strong in a backtest, but whether its edge survives live costs, execution frictions, and changing market conditions.
Why do AI trading bot backtests often look much better than live results?
Backtests often assume cleaner fills, stable spreads, low slippage, and ideal execution. They can also be distorted by overfitting, data leakage, and excessive parameter tuning, which makes simulated performance look more robust than it really is.
What does profit really mean for a trading bot?
Profit should be judged net of commissions, spreads, slippage, swap or financing charges, borrow fees where relevant, and taxes. It should also be considered alongside drawdown, leverage, and capital efficiency, not just headline returns.
Which live-market frictions hurt trading bots the most?
The biggest ones are spreads, slippage, latency, and liquidity. These matter most for short-term or high-turnover systems, where a small theoretical edge can disappear once real execution costs are applied.
Why do AI bots fail during regime shifts?
Many bots are trained on patterns that hold only under certain volatility, liquidity, or correlation conditions. When those conditions change, signal quality, position sizing, and risk assumptions can break down quickly.
Does AI automatically adapt to changing markets?
Not reliably. Some machine learning systems can adapt faster than static rule-based models, but adaptation alone is not proof of robustness. It depends on retraining methods, validation discipline, execution quality, and risk controls.
What evidence is credible when evaluating an AI trading bot?
The strongest evidence includes verified live track records, broker statements with enough history to inspect costs and drawdowns, and real-money forward tests across different market conditions. Demo accounts and screenshots are much weaker proof.
What metrics matter more than win rate?
Look at net profit after costs, maximum drawdown, expectancy per trade, profit factor, Sharpe or Sortino ratio, turnover, average trade, and stability across subperiods. A high win rate alone can hide poor risk-reward and fragile performance.
Can retail traders realistically run profitable AI trading bots?
Sometimes, yes, especially in slower, more liquid markets where latency matters less. Retail traders are usually at a disadvantage in speed-sensitive strategies, but they may still compete with simpler, lower-turnover systems that are validated honestly.
How should I test an AI trading bot before risking serious capital?
Start with cost-adjusted backtests, then move to small real-money forward testing. Compare expected edge per trade with likely round-trip costs, review how the bot behaves under wider spreads and higher volatility, and increase capital only if live results remain stable.